
Mythos Brought It to the Boardroom. Now Weaponize Defense.


I ran a webinar this week called "Inside the Mythos Moment: A Practitioner's Read for CISOs and Their Boards." I didn't want to write another recap of what Anthropic announced. There are plenty of those. I wanted to walk through what the moment actually means, how to read it correctly, and what practitioners should do differently as a result of it.
This post is the written version of that argument.
TL;DR: Mythos matters because it brought this conversation into boardrooms and made it accessible to non-technical leaders. Reactive cybersecurity is no longer valid. Proactive is the only way forward, because defenders no longer have time to react. But proactive is not just AppSec: think full-kill-chain offensive security, because this is what adversaries are already doing today, far beyond AppSec with Mythos. Once you understand that proactive full-kill-chain cyber is a must-have preventative program, the next step is learning how to operationalize it across your organization. This is what’s really hard, and why Cracken exists.
What actually changed when Mythos was announced?
The honest answer is: less than the headlines suggested, and more than the critics admitted.
Mythos didn't create the capability. AI was finding bugs before April 7. Teams were building offensive AI workflows before April 7. Adversaries were already using agentic tooling before April 7. What Mythos did was cross enough capability thresholds, at sufficient public visibility, that the conversation landed in boardrooms. Non-technical executives started asking their CISOs about it. Investors started asking founders. That surfacing matters, even if the underlying technical reality was an iterative improvement rather than a category-creating event.
The framing I kept returning to, both in the webinar and in the conversations I had in the weeks before it, is this: the category was already real. Mythos made it visible. And that visibility is actually useful, because it gives practitioners an opening to have conversations they've struggled to have for years.
The critique I have some sympathy for is the cost argument, though not entirely. Some observers called Mythos expensive and impractical. That critique misses what Anthropic was actually trying to demonstrate. They weren't optimizing for cost. They were proving that certain capability thresholds, previously considered out of reach, were now solvable. The scaffolding they used for their AppSec work was basic, say, ranking files by risk level before passing them to a sub-agent. That's not how you build a production system. But it was enough to demonstrate the capability, and that was the point.
The AISI evaluation from the UK was the most useful independent analysis I saw. It confirmed real new capability, while also noting that OTICS results were weak, that Mythos sometimes hallucinated credentials and findings, and that alignment issues persisted. Both things are true at once: Mythos represents a genuine step forward, and it comes with limitations that any serious operational deployment would need to account for.
Why is reactive cybersecurity no longer viable?
This is the structural argument underneath everything else, and it's the one I spend the most time on with security leaders.
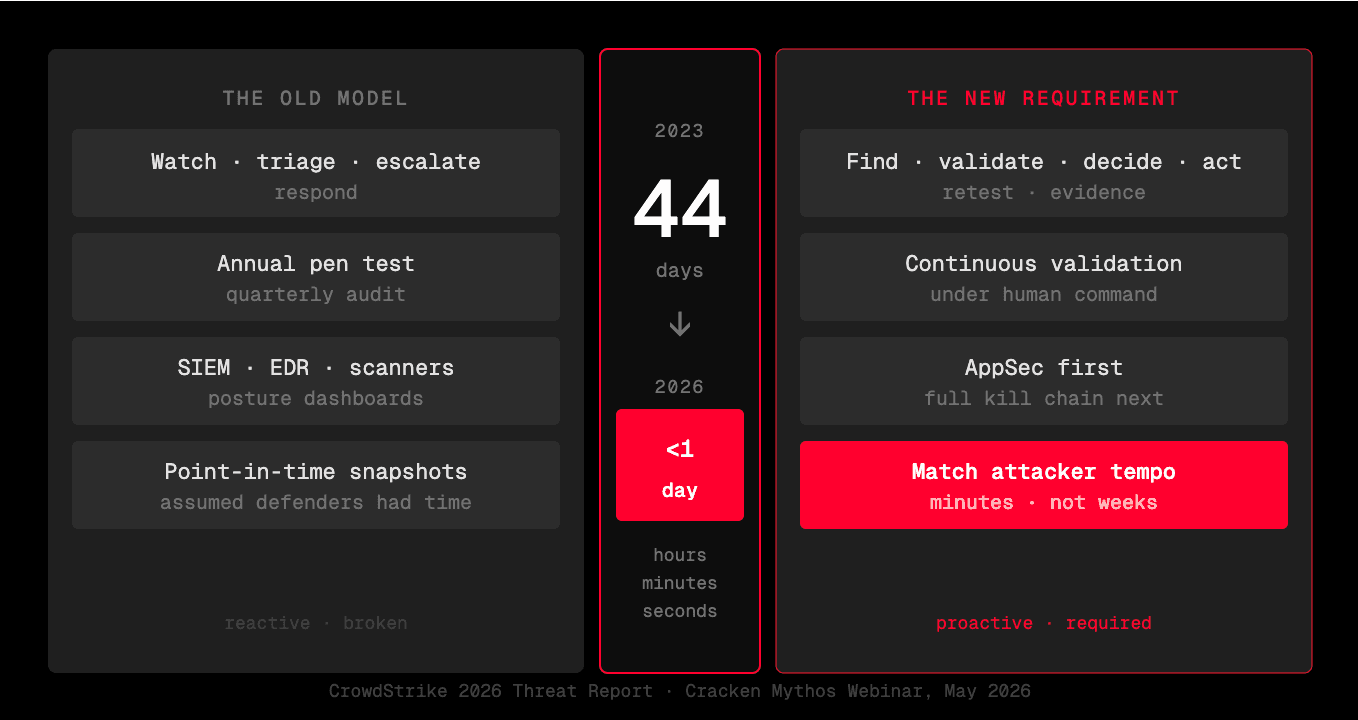
Time to exploit has collapsed. In 2023, the median time from vulnerability disclosure to active exploitation was 44 days. By 2026, we're measuring it in hours, sometimes minutes, sometimes seconds. I've personally watched this: using Shodan sensors and threat intelligence feeds, an attacker operationalized an exploit in the time it takes to read an email. The window that reactive security programs were designed to operate in no longer exists.
The old job was: watch, triage, escalate, respond. SIEM, EDR, scanners, posture dashboards, annual pen test, quarterly audit. That model assumed defenders had time. They don't. Adversaries are not waiting for your ticket queue to clear.
The other perspective on this is costs and resources-wise. The analogy I use here is from conventional warfare and the economic shifts produced by cheap drones in wars.
Before this shift, many important targets were protected by the economics of attack. If an adversary wanted to get to the crown jewel, they often had to expend significant resources to gather intelligence, plan an attack, and launch an expensive, precise cruise missile. In that world, expensive reactive systems, like a Patriot battery, could still make sense because the attacker was paying an even higher price. The economy was like in strategy games, when you have +2 in battle for defense.
Cheap drones changed that in wars. AI changes this in cyber.
As the attacker no longer needs to spend a missile to hit a weak point, AI makes the adversarial side cheaper: cheaper recon, cheaper phishing, cheaper exploit development, cheaper malware variation, cheaper lateral movement. With drones in the physical world and AI in the digital world, the attack is now cheaper. Now the defender pays the tax to defend: alerts, triage, escalation, investigation, incident response, downtime, recovery, legal, and board reporting. It’s now -2 for defense.
The answer is not to keep buying more reactive interception forever or to make it more effective. It is fundamentally questionable whether reactive interception systems can be made more effective than attacker systems with the same AI at this point. In any case, if every cheap AI-driven attack creates an expensive defensive process, the defender is losing the economics.
The answer is to make the system resilient to new, more precise, cheaper attack types by being proactive — using the time before the attack as the defender’s resource — testing your system with the same precise, cheap attacker-grade weapons to identify and remediate attack paths.
This is why proactive cybersecurity is the only architecture that makes sense given the current threat tempo. Organizations that are still running purely reactive programs are not operating in the same world as their adversaries.
Does the model matter more than the harness?
This is the question that separates practitioners from observers, and the answer is unambiguous: the harness matters at around the same level as the model.
The data from Terminal-Bench 2.0 is instructive. ForgeCode running on Claude Opus 4.6 achieved ~80% (79.8%) score on that benchmark. Claude Code on the same underlying model scored ~60% (58%). Same model, different harness, ~20% spread. That's the harness effect, quantified.
But the Claude Code with Mythos achieved roughly the same 80% (82%) as a good harness with a worse model on the same benchmark. That's the model effect, quantified.
Do the model restrictions matter for adversaries?
GPT-5.5 is already at the Mythos level.
And as we discussed, a well-built harness running on an open model that's already widely available without any guardrails today can match Mythos-level performance. You don't need to wait for access to the most restricted frontier model.
The adversarial side understands this. They're not waiting for permission to access Mythos.
The Mercor breach, disclosed in late April, showed a Discord-linked group accessing Mythos within hours of its announcement, not through any technical wizardry, but through a supply chain failure.
Furthermore, Mythos is still censored, as reported in the AI Alignment tests. Adversaries are running beyond that. They're using account farms, API aggregators, jailbreak-as-a-service from darknet marketplaces, and specialized uncensored open-weight models to achieve capability beyond what is available for good folks.
Gating is friction. Guardrails are friction. These are not containment.
The practical implication is that your operationalization strategy should not be dependent on access to any single restricted model. You need the right environment, the right orchestration, the right verifiers, the right evidence layer, the right human-in-the-loop UX, and the right adversarial-grade capabilities.
What did Mozilla's deployment actually demonstrate?
The Mozilla case is the most instructive public example of what an operationalized component of proactive security, called Application Security, looks like at scale, and it's worth dwelling on.
Firefox 150 shipped 423 security fixes in April. 271 of those were identified by Mythos. Anthropic found 180 sec-high issues, 80 sec-moderate, 11 sec-low. They also declined to publish many of the specific vulnerabilities, because the CVS scores were high enough that public disclosure would have immediately weaponized them. The comparison between Opus 4.6 (2 working exploits across several hundred attempts) and Mythos (181 working exploits on the same codebase) makes the capability gap concrete.
But the more important observation is structural. Mozilla executed all four phases of a mature security loop: discovery, validation, hardening, release. Most organizations I talk to have one or two of those phases. They find things, but don't validate them. Or they validate, but the remediation backlog is never actioned. Mozilla ran the full loop, at scale, in production, and shipped. That's what it actually looks like.
The question for most security programs isn't whether Mythos or Daybreak or GPT-5.5 can find issues. They can. The question is whether your organization has the process infrastructure to absorb the findings and convert them into fixed, validated, regressed, evidence-backed remediation. That loop is the work. The model is just the front end of it.
The defender's structural advantage: Attackers guess, Defenders know
There's a framing I come back to often because it's genuinely true and genuinely underappreciated. Defenders have an intrinsic white-box advantage that attackers can never fully close.
An attacker trying to exploit your system has to infer from the outside. They conduct OSINT. They gather information about your tech stack from job postings, conference talks, LinkedIn profiles, leaked internal documents. They guess at your configurations and iterate until something works. Every step costs them resources and time.
You already know the answers. You have your source code. You have your infrastructure as code, your CI/CD pipelines, your IAM configurations, your telemetry, your identity graph. You know what the system is supposed to do, which means you can reason about where it might fail. The GTIG 2FA-bypass case from the Google threat report is illustrative: the attacker reasoned over public code alone. The defender could have reasoned over public code plus deployment context plus intended behavior, and found the flaw first. The defender didn't.
Most organizations leave that white-box advantage trapped in disconnected systems. The source code is here, the configs are there, the CI/CD is somewhere else, the telemetry is in yet another tool, and none of it is connected to anything that could reason over it systematically. Connecting that context to execution is, say, what closes the gap between theoretical advantage and operational advantage.
What does the adversary workflow actually look like today?
The Google GTIG report published in May is the best recent public picture of how adversaries are operationalizing AI, and I'd encourage anyone who hasn't read it to do so.
The adversary stack is not a single model. It's a workflow. Exploit development using AI-assisted logic flaw discovery, including the 2FA bypass technique. Jailbreak memory systems drawing on legacy vulnerability corpora including over 85,000 cases from the Wooyun archive. Scaled prompting, where APT45 was documented sending thousands of repetitive prompts to iterate toward working exploits. Automated spearphishing campaigns that generate personalized lures at scale. Autonomous malware, including LAMEHUG, which is Russia-linked, uses open-weight model access via Hugging Face, and was deployed against Ukrainian critical infrastructure. Agentic tooling including Hexstrike, Graphiti, Strix, and OpenClaw. Account farms, anti-detect browsers, API aggregators. And increasingly, attacks targeting AI integration layers directly.

The race is workflow against workflow. Restricting access to one frontier model does not stop any of this. Adversaries have multiple paths to equivalent capability, and they're using all of them. The relevant competition is not whether defenders have access to Mythos. It's whether defenders can operationalize their defensive loop faster than adversaries can operationalize their offensive one.
What questions should CISOs be asking their boards, and what questions should boards be asking back?
The board conversation has changed since Mythos. Questions that used to require context are now arriving without it. Non-technical directors are asking about AI and cybersecurity, and many security teams don't have answers ready, because they've been tracking the technical developments without translating them into board-defensible language.
The four answers boards need are: what changed, what didn't, what we're doing about it, and what's next.
What changed (2-3 years short-term in corporate representation of time 🙂) is that AI can find and validate vulnerabilities at scale, and the decision cycle has compressed from years to weeks. Mozilla shipped 271 AI-identified fixes in a single cycle. That's the proof point.
What didn't change is that AI doesn't auto-fix anything. Less than 1% of Mythos-identified vulnerabilities in Mozilla's codebase were actually patched without human involvement. Triage, decision-making, and verified remediation still require human authority and engineering capacity. The loop still requires humans operating it.
What we're doing is the operationalization work: building the find, validate, fix, retest evidence loop on critical narrow surfaces (e.g., AppSec, or Webapp & Network Pentest), routing models by task fit, keeping humans in command.
What's next is extending that loop to the full kill chain — identity, cloud, endpoint, human, and AI attack surfaces — because adversaries already operate there.
The answer the board actually needs is not a vendor's promise. It's a test result. Can we validate a real end-to-end attack path to a crown jewel? When did we last do that? What did we find? What did we fix? What evidence do we have? That's the conversation that produces board-defensible answers.
Where should organizations start?
The practical question I get most often is some version of: "This is compelling, but where do we actually begin?" The answer depends on where you are.
If you don't have a red team or proactive security program yet, the first questions are foundational. Are you running any proactive testing at all, or only reactive defense? When did you last validate, end to end, a real path to a critical asset? Who owns the decision to test your own systems (important if it is you or an external service provider)? Can you reproduce and validate AI-generated findings before they sit in a queue? Where are your current blind spots, in identity, cloud, third-party integrations, endpoint, human?
If you already have a red team, the questions shift to operationalization. Has your team moved to AI-assisted discovery? Are you running continuous validation or still periodic? Can your team match adversary tempo, minutes, not weeks? Have you extended beyond application security or pentest to full kill chain coverage? Is your evidence pack ready for a board presentation, a regulator review, or a customer security questionnaire?
The sequencing I recommend is: AppSec or Pentest first, because it's the highest-signal starting point and the one with the clearest operationalization path today. Full kill chain next (with spearphishing, malware research, post-exploit, etc.), because adversaries aren't limiting themselves to application security or narrowly scoped pentests, and neither should defenders. The program that covers only the technical part of the digital system is covering only part of the attack surface that your adversaries are already mapping.
The Loop That Matters
The framing I return to throughout this argument is the find, validate, decide, act, retest, evidence loop. It's not complicated. What's hard is building the infrastructure to run it continuously, at scale, with human command and team synchronization at every important decision point.
The decision at the "act" stage is a portfolio problem. You won't fix everything. Some paths get patched and regression-tested. Some get mitigated with compensating controls, which are then validated under the relevant attack path. Some risks get formally accepted, logged, and put on a review cadence. Some surfaces get redesigned when the same class of vulnerability keeps reappearing. Some assets get deprecated when they're no longer worth defending. The board question is which paths are still open this week, and what decision was made about each one.
Cyber advantage comes from the loop you operate. Not from the model name on your procurement contract.
If you're ready to run the loop, not just read about it
Every conversation I have with a CISO after a moment like this ends the same way. The framing lands. The urgency is clear. And then, when they understand what to do, they ask how do it?
Cracken exists to answer that question operationally. We're the AI platform built specifically for this — attacker-grade, uncensored AI under full human command, designed for the find, validate, decide, act, retest, evidence loop that most organizations know they need and few have actually built. We work with enterprises in banking, critical infrastructure, and government, environments where fully autonomous tooling is a non-starter and where the robust and safe architecture isn't a compromise; it's an operationalization requirement.
If you want to validate where your program actually stands, we run proof-of-concept engagements that produce a real kill-chain finding, not a dashboard. That's the starting point. Talk to us at cracken.ai.
FAQ
What is Anthropic's Mythos and why does it matter for enterprise security?
Mythos is Anthropic's frontier AI model, announced on April 7, 2026, which crossed new capability thresholds in offensive cybersecurity tasks. In independent evaluations by the AISI in the UK, it achieved a 73% success rate on expert CTF tasks. In production with Mozilla, it identified 271 vulnerabilities in the Firefox codebase, including 180 classified as high severity. Its significance for enterprise security is not that it created new risk categories, but that it brought a conversation about AI-enabled offensive operations into boardrooms and mainstream discourse, creating both urgency and an opening for organizations to accelerate their proactive security programs.
What is Adversarial Exposure Validation (AEV) and how does it differ from traditional penetration testing?
Adversarial Exposure Validation is the practice of continuously validating which exposures in your environment are actually exploitable, in what sequence, and with what real-world impact. Traditional penetration testing produces point-in-time findings, typically annually or quarterly, which may or may not reflect the current exploitability of those issues in your actual environment. AEV operates continuously, under human command, and produces evidence of real kill-chain reproducibility rather than theoretical vulnerability lists. The distinction matters because AI has compressed exploit development timelines from months to hours, making point-in-time assessments structurally inadequate for the current threat tempo.
Does my organization need access to Mythos-level AI to run proactive security?
No. GPT-5.5, already broadly available, was evaluated by AISI as performing at Mythos level on expert cyber tasks. Also, the harness and scaffolding you build around a model matter just as much as the model itself. Data from Terminal-Bench 2.0 shows that ForgeCode running on Claude Opus 4.6, a commercially available model, achieved 79.8% performance on a benchmark where Mythos achieved roughly 80%. You do not need to wait for access to a restricted frontier model. You need to build the right orchestration, verification, evidence, and controls architecture around models you can already access.
How are adversaries accessing Mythos-level AI capability today?
Through multiple vectors that do not depend on authorized access. These include account farms and API aggregators that relay requests through compromised credentials, jailbreak-as-a-service tools available on darknet marketplaces that remove AI alignment guardrails, open-weight models, and direct exploitation of organizations that have legitimate access to frontier models. The Mercor breach, disclosed in April 2026, demonstrated that adversaries reached Mythos within hours of its announcement through supply chain compromise, not technical attacks on Anthropic's infrastructure. Restricting model access reduces friction for adversaries. It does not stop them.
What is the "defender's white-box advantage" and why isn't it being used?
Defenders have inherent knowledge that attackers must expend significant resources to approximate: your source code, infrastructure configurations, CI/CD pipelines, IAM settings, telemetry, and the intended behavior of your systems. Attackers must infer all of this from outside, through OSINT and iterative experimentation. This gives defenders a structural cost advantage when finding vulnerabilities, because you can reason over the actual system rather than guessing at it. The reason this advantage isn't being used is largely architectural: source code is in one system, configs are in another, telemetry is in a third, and none of it is connected to an execution environment that can reason over it systematically and find exploitable paths before attackers do.
What is the difference between AppSec and full kill chain proactive security?
Application security focuses on finding and fixing vulnerabilities in software code, typically through white-box scanning and exploit validation. Full kill chain security covers the entire attack path an adversary might use: threat intelligence and OSINT, reconnaissance, vulnerability chaining, lateral movement, privilege escalation, social engineering, phishing resilience, incident response, cloud and IAM privilege abuse, identity and session exploitation, and more. Most AI-powered security tools currently address only AppSec. Adversaries are already operating the full chain. Organizations that limit proactive testing to AppSec are validating part of their attack surface while leaving the rest unexamined.
What should a CISO tell their board after the Mythos moment?
Four things: what changed (AI can find and validate vulnerabilities at scale; the decision cycle has compressed from years to weeks; adversaries are already using these capabilities), what didn't change (AI doesn't auto-fix anything; human authority is still required for triage, decision, and verified remediation), what your organization is doing (building the find, validate, fix, retest, evidence loop on your most critical surfaces, under human command), and what's next (extending that loop from AppSec to the full kill chain). The board wants defensible proof, not vendor reassurance. The answer is a test result: here is a real path we validated to a critical asset, here is what we found, here is what we fixed, here is the evidence.
How does Cracken approach the human-in-the-loop requirement for regulated enterprises?
Cracken is built around the principle that machine execution under human command is not a constraint imposed from outside but the architecture that makes adversarial-grade AI safe for deployment in regulated environments. The platform routes frontier commercial models, open-weight models, and proprietary uncensored cyber models by task fit, using specialized scaffolding built for full kill chain operations. Human operators approve scope, review findings, make remediation decisions, and sign off on evidence before it goes anywhere. This is the architecture that allows the most capable, uncensored AI to operate inside enterprise environments without the risks associated with fully autonomous systems, and it's why CISOs in banking, critical infrastructure, and government have been the earliest adopters.
Sources & Further Reading
Mythos announcement / Project Glasswing Anthropic — Project Glasswing official announcement
AISI UK evaluation — 73% CTF success rate & "The Last Ones" simulation AISI — Our evaluation of Claude Mythos Preview's cyber capabilities
GPT-5.5 reaching Mythos-level performance AISI — Our evaluation of OpenAI's GPT-5.5 cyber capabilities
Terminal-Bench 2.0 — harness vs. model performance Terminal-Bench 2.0 leaderboard · ForgeCode on Claude Opus 4.6 — Tensorlake writeup · ForgeCode harness engineering deep dive
Mozilla Firefox 150 — 271 vulnerabilities found by Mythos Mozilla Hacks — Behind the scenes hardening Firefox · The Next Web — Mozilla fixes 271 Firefox vulnerabilities
Mercor breach / unauthorized Discord access to Mythos DataBreachToday — Discord group uses Mythos · Tom's Hardware — How unauthorized users accessed Mythos
Google GTIG report — adversary AI workflows, APT45, OpenClaw Google Cloud Blog — Adversaries leverage AI for vulnerability exploitation · CNBC — Google thwarts AI-enabled mass exploitation attempt
Artem Sorokin is CEO and Co-Founder of Cracken (cracken.ai), an agentic AI platform for proactive cybersecurity. He is a Ukrainian-born software engineer, ethical hacker, and MIT-affiliated business professional who works with enterprises and critical infrastructure organizations across the US and Europe. The Cracken team runs regular webinars on AI and offensive security developments. The next session covers the new compliance landscape in the US.