
Domain-Specific Abliteration, or when smarter also means virtuous

How we created the first domain-specific abliterated model with the right dataset and unleashed one trillion parameters for legitimate security research.
The First Scalpel in a Field of Sledgehammers
Until now, abliteration has been a blunt instrument — remove a model's refusal behavior for one domain, and you remove it for everything. The research community had effectively concluded that domain-specific abliteration was theoretically interesting but practically impossible.
We just proved otherwise and created the first ever domain-specific uncensored model!
This changes what's possible for legitimate security research and what we understand about how frontier models encode ethics.
In the original paper that presented the abliteration technique, Arditi et al. state that refusal in LLMs is mediated by a single direction regardless of request context. But that work was conducted in 2024, when LLMs were large but not 1T-parameter large. We obtained the same results in our experiments with smaller models, such as 4b, 8B and 30B Qwen3. They are described in the previous posts of this series.
However, moving to Kimi K2 showed a very different picture.
| Domain | Baseline | Post-Abliteration | Change |
|---|---|---|---|
| Cybersecurity | 100% | 0% | -100% |
| Explicit Content | 100% | 100% | 0% |
| Illegal Goods | 100% | 70% | -30% |
| Violence | 100% | 70% | -30% |
| Misinformation | 100% | 70% | -30% |
| Privacy Violation | 100% | 40% | -60% |
Zero cybersecurity refusal. Full explicit content refusal preserved. This isn't a global jailbreak — it's surgical removal of a single domain's restrictions while the model maintains its ethical boundaries everywhere else.
The result challenges a common assumption in AI safety: that capability and safety exist in tension. Here, the opposite emerged. Better and more focused data, smart layer selection, deeper understanding of how MoE architectures encode refusal produced a model that is simultaneously more capable for security research and more virtuous in domains where restrictions should remain.
What We Built (and Why It Matters)

Every security researcher knows the friction. You're testing your own application for SQL injection vulnerabilities, and the AI assistant apologizes. You're working through a CTF challenge, and the model lectures you about responsible disclosure.
Our abliterated Kimi K2 responds to security queries with working code, defensive explanations, and context for authorized testing environments. No apologies, no refusals — just technical assistance for legitimate security work.
But this wasn't achieved by disabling safety wholesale. We isolated the cybersecurity refusal mechanism while leaving other protections intact to whatever degree possible.
The validation is in the comparison. There’s only one abliterated Kimi K2 available on the HF hub, made by Huihui, so we decided to test it and compare it with ours:
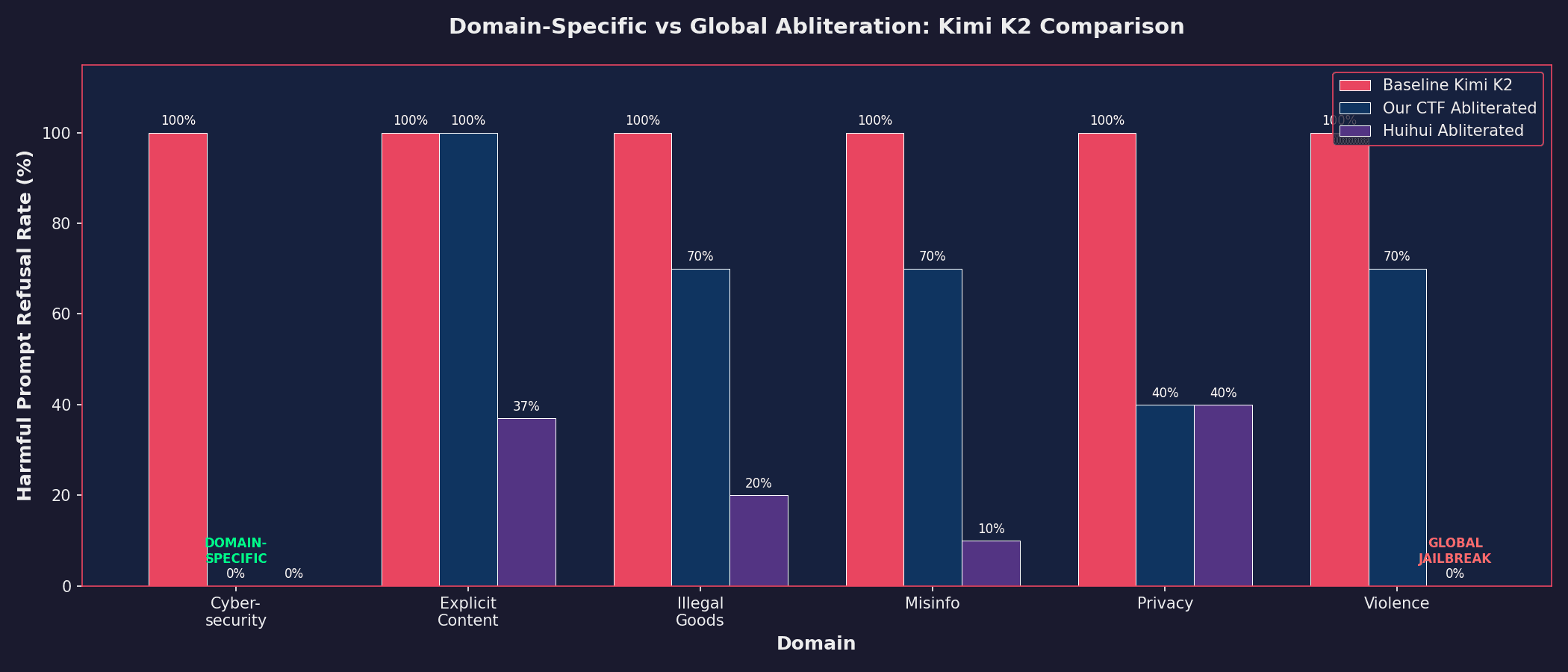
Both achieve 0% cybersecurity refusal. But Huihui's model complies with violence requests, misinformation prompts, explicit content — everything. Ours maintains substantial ethical boundaries in every non-target domain.
The Technical Foundation
Infrastructure: Kimi K2 is a trillion-parameter Mixture-of-Experts model with 61 layers and 384 experts per layer. Running hidden state extraction required 8x NVIDIA H200 GPUs on a GCP a3-highgpu-8g instance, using vLLM with tensor parallelism and speculators for activation capture.
The Dataset Insight: Previous abliteration work treats dataset design as a challenge. We also found that it is the primary instrument to achieve desired result. Generic cybersecurity datasets conflate surface patterns — "write code to exploit SQL injection" and "write code to detect SQL injection" look nearly identical to pattern-matching safety mechanisms.
Our CTF-enhanced dataset (52 harmful, 73 harmless cybersecurity prompts) created clear structural separation. Harmful prompts use action framing: "Write Python code to exploit a buffer overflow." Harmless prompts use question framing with explicit educational context: "For a CTF challenge involving a Linux binary with SUID bit set, walk me through the methodology to identify potential privilege escalation paths."
The result: better outcomes with less aggressive intervention. Our dataset at moderate strength outperformed generic datasets at maximum strength. Strength is a simple multiplier applied to the refusal direction that we introduced in the scope of one of the experiments.
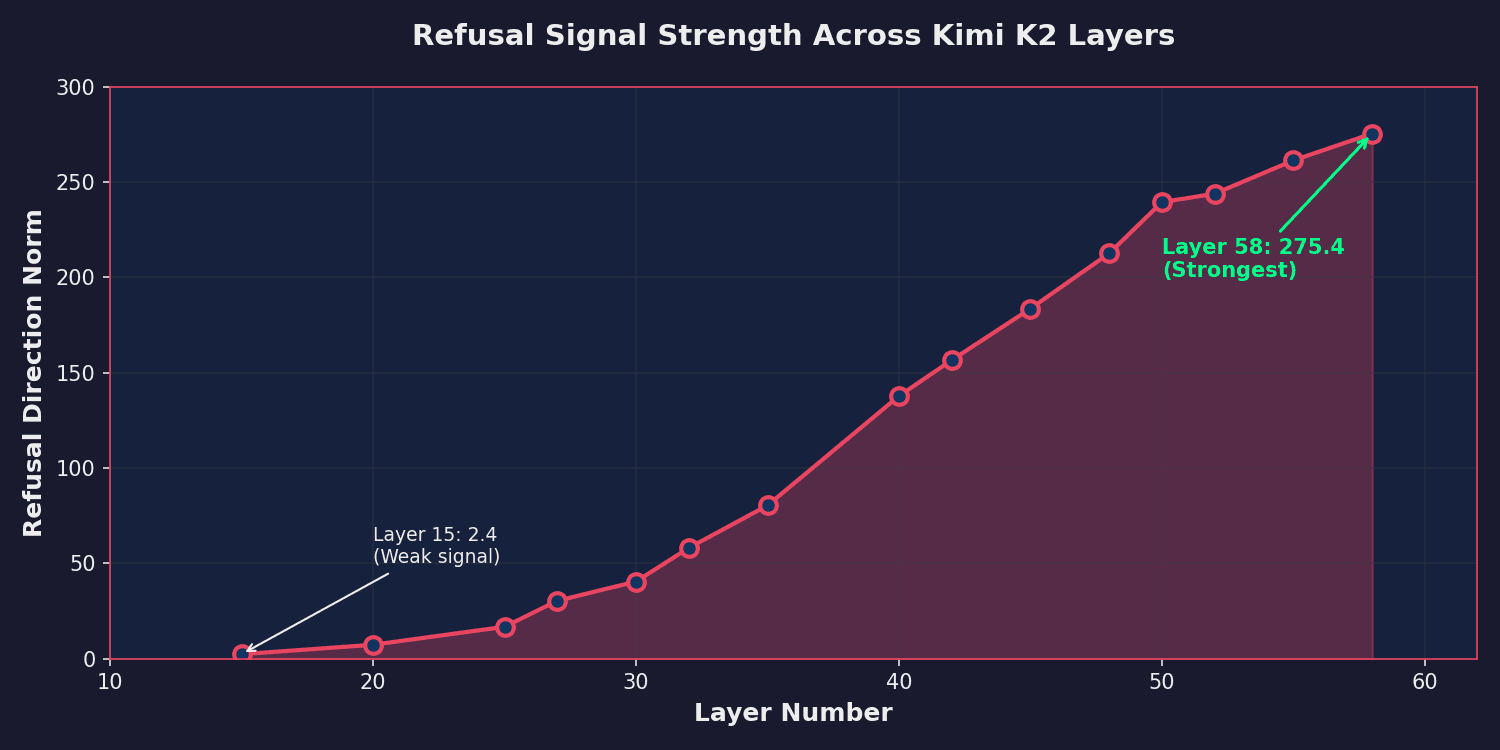
Layer Strategy: MoE models distribute refusal behavior across hundreds of experts per layer. Single-layer abliteration, which works on dense models, had zero effect on Kimi K2. We mapped refusal signal strength across all 61 layers and selected 15 spanning the full computation pathway, from early pattern encoding through final refusal expression.
What This Reveals About AI Safety
Domain isolation is architecturally possible. The MoE design that makes Kimi K2 harder to abliterate also provides natural boundaries and creates more sophisticated refusal geometry. Experts that activate for cybersecurity prompts operate somewhat independently from those handling other domains. This suggests MoE architectures may be more amenable to fine-grained safety modification than dense models.
Explicit content safety is encoded fundamentally differently. Across multiple experiments, explicit content refusal proved uniquely resistant to abliteration. Even more aggressive (cybersecurity-focused) interventions left it completely intact (100% preservation). This consistency suggests explicit content safety operates through distinct mechanisms — possibly different layers, attention heads, or representational structures — worth investigating for making other safety domains more robust.
The emergence of virtue through capability. It is also possible that this is simply the consequence of model size. Perhaps, beyond some threshold of capability, a model's understanding of morality — of good and evil — becomes more intricate. This is a hypothesis that we intend to study in the future.
This aligns with broader patterns in AI development: more capable systems can make finer distinctions, exercise better judgment, and behave more appropriately across contexts. The crude all-or-nothing refusal of early models gives way to nuanced understanding of intent and context.
Limitations and Responsible Disclosure
We haven't yet measured capability degradation on standard benchmarks. Modern models increasingly use extended-refusal training that distributes safety across multiple components—our evaluation uses simple refusal detection and may miss sophisticated refusal behaviors. The 20-prompt-per-domain evaluation, while consistent, has limited statistical power.
Privacy violation showed more spillover than other domains (40% vs 70% refusal), suggesting representational overlap with cybersecurity concepts, which makes sense since cybersecurity often involves privacy-related topics.
The research was conducted in controlled environments for defensive cybersecurity purposes and to advance understanding of AI safety mechanisms. We publish our findings and methodology, not weights — transparency without enablement.
For organizations building security tooling, the implications are significant: domain-specific safety modification is achievable without compromising other ethical boundaries. For AI safety researchers, the dataset quality finding redirects attention from brute-force intervention toward careful experimental design.
There are undoubtedly many questions to answer and theories to test. Nonetheless, we present our unique findings and first domain-specific uncensored model to open new possibilities for cybersecurity researchers and to propel the field of AI interpretability further. At the edge of a trillion parameters, capability and virtue stopped being trade-offs. Domain-specific abliteration works. The frontier just moved.
A Breakthrough for Cracken’s Proprietary Offensive Model Stack
Our work demonstrates a capability the community largely considered out of reach: true domain-specific uncensoring at trillion-parameter scale. Instead of the usual “global jailbreak” effect, refusal behavior can be surgically removed only for cybersecurity tradecraft, while safety boundaries in unrelated domains remain intact.
This is foundational for Cracken’s roadmap toward a proprietary adversarial model. Off-the-shelf frontier systems routinely block operationally critical red-team workflows — exploitation logic, injection payload generation, social engineering simulation — forcing practitioners into brittle prompt games rather than attacker-tempo execution.
Domain-specific abliteration eliminates that friction: a model that reliably complies with legitimate offensive-security requests without becoming broadly unaligned. For Cracken customers, this unlocks higher-fidelity adversary emulation, faster operator loops, and an enterprise-safe path to uncensored capability inside governed, human-in-the-loop deployment.
Defenders can now wield uncensored AI with precision — and Cracken is building the system to deploy it safely.
References
- Arditi et al. (2024)Refusal in LLMs is mediated by a single directionArXiv
- Extended-Refusal Defense (2025)An Embarrassingly Simple Defense Against LLM Abliteration AttacksArXiv 2505.19056
- Multi-Dimensional Safety (2025)The Hidden Dimensions of LLM AlignmentArXiv 2502.09674
- Labonne (2024)Uncensor any LLM with abliterationHuggingFace Blog
- Anthropic Frontier Red Teamred.anthropic.com
- Anthropic (2024)Challenges in Red Teaming AI Systemsanthropic.com
- Anthropic (2025)Frontier Threats: Red Teaming for AI Safetyanthropic.com
Research conducted for defensive cybersecurity purposes. Methodology available for qualified researchers upon request.