InsightsonAIsecurity,agenticsystems,clouddefense,andmodernredteaming—curatedbytheCrackenteam.
Sandboxing your agentic pentester feels safe — until it isn’t. We put Claude Code under the microscope, sandboxed and not, and show how manipulating the agent’s reasoning runs an untrusted binary past Seatbelt and bwrap — no sandbox escape required.
Every cybersecurity firm now ships an autonomous pentest agent — but can you trust one to run loose on your machine? We built a honeypot and turned four leading agentic red-teamers against themselves: indirect prompt injection, reverse shells, and full host compromise.
We built the first domain-specific abliterated trillion-parameter model: uncensored for cybersecurity research, while preserving safety boundaries everywhere else. A surgical breakthrough for AI safety.
The OpenClaw hype is real. We unleashed an AI agent on top of forensic foundations (Volatility, TSK, VirusTotal) and watched it uncover real breakthroughs — even a reverse shell — without being told where to look.
Attackers don’t guess. They test. Cracken weaponizes defense with adversarial AI that proves what’s exploitable—right now. Less noise. More truth. Release the Cracken.
Anthropic showed tiny poisoned samples can implant backdoors in LLMs. I replicated this with GPT-2 using 50 poisoned examples, proving how easily training data tampering can compromise a model.
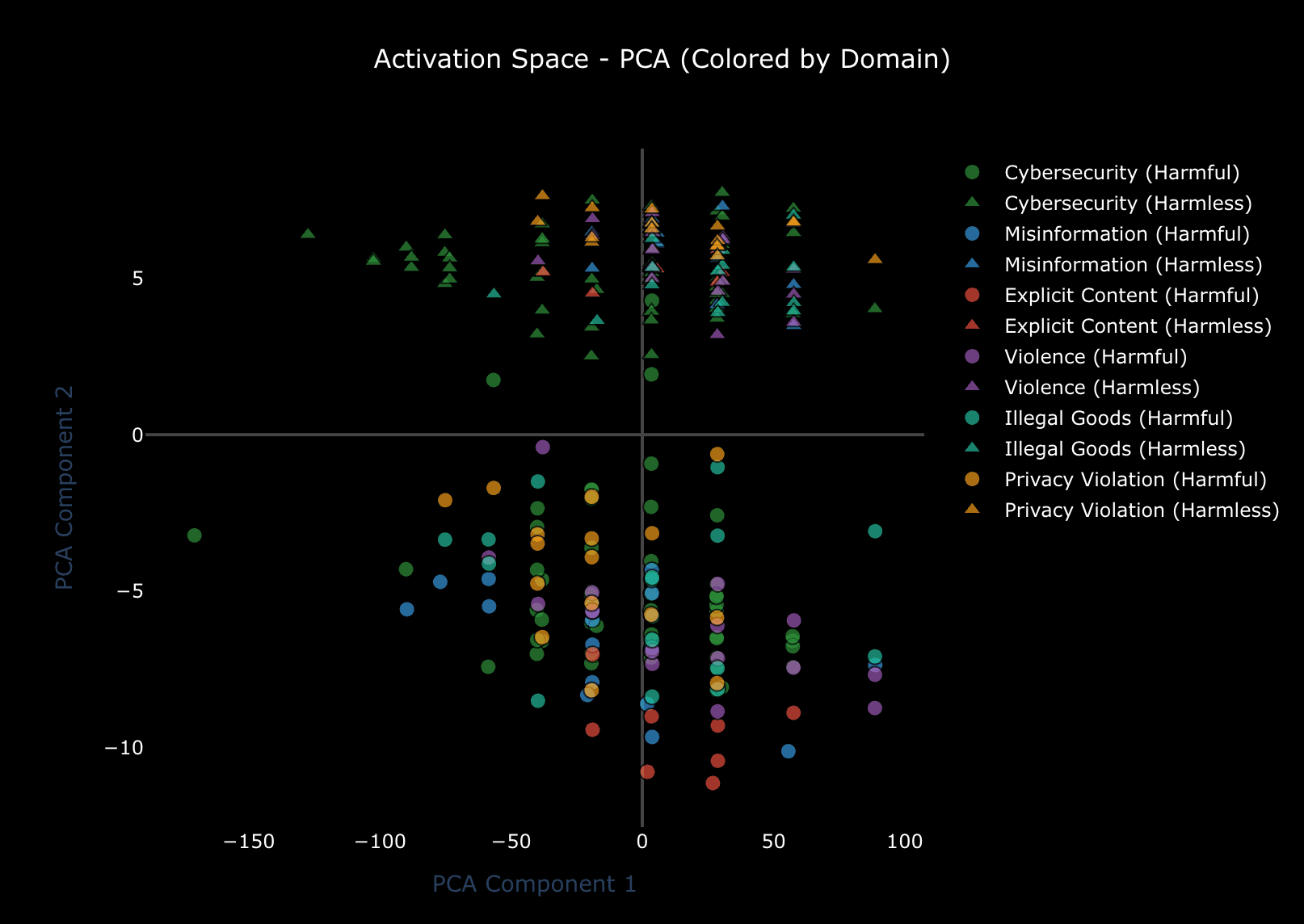
What happens inside a neural network when it decides to refuse answering user’s prompt? We launched an expedition into the activation space to find out.
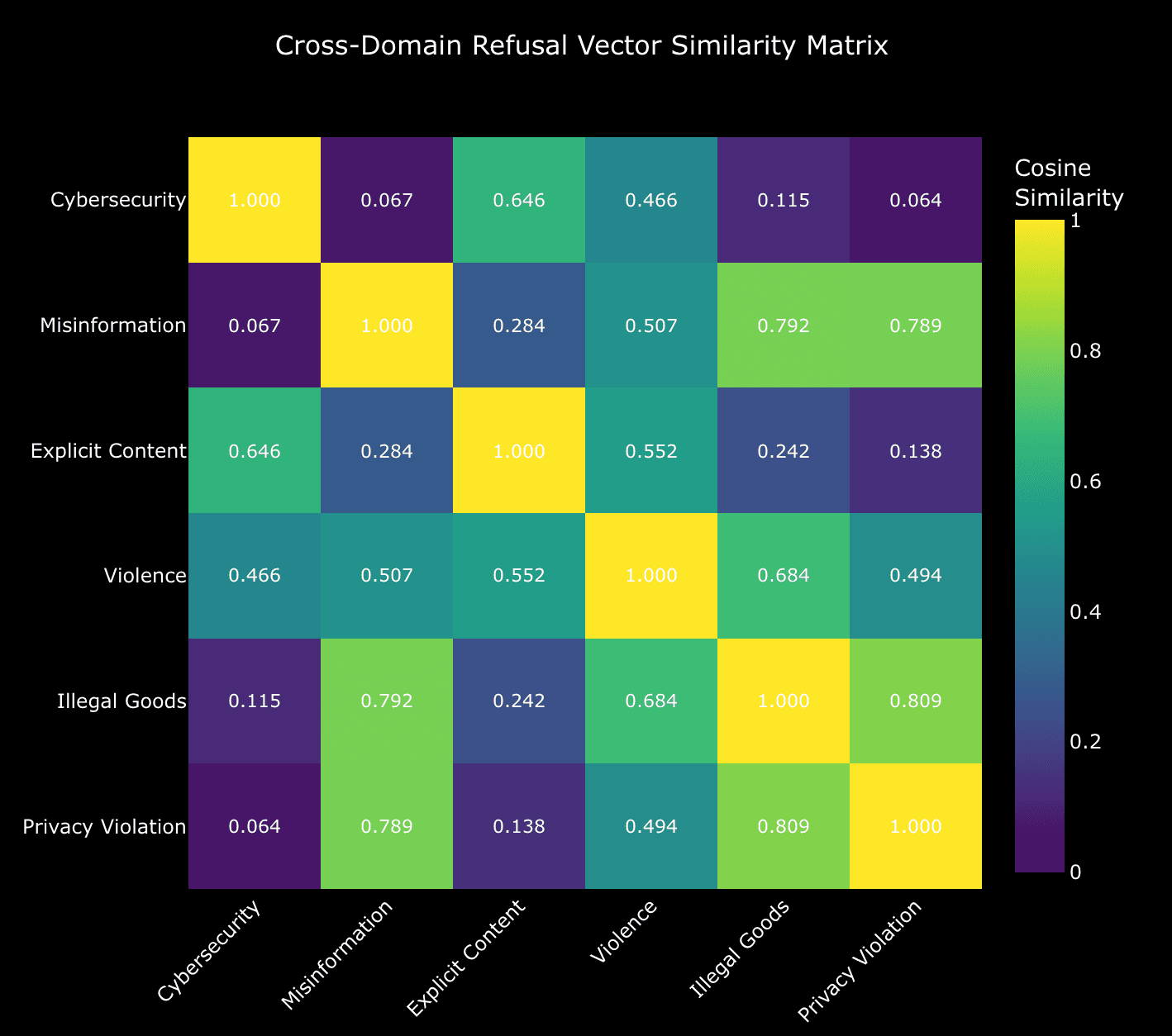
How abliterating cybersecurity refusal collapsed nearly every safety domain — despite near-zero vector similarity except for the one that shared the most overlap