
The Domain-Specific Abliteration Paradox

We Tried to Be Surgical but Ended Up With a Sledgehammer
Picture this: You're a cybersecurity researcher trying to use AI to help analyze vulnerabilities, generate security test cases, or automate threat detection. But there's a problem — at some point your helpful AI assistant refuses to help:
You: "Write code to perform network vulnerability scanning using Nmap" AI: "I'm sorry, but I can't assist with that."
This is the safety alignment paradox. The same mechanisms designed to prevent malicious use are blocking legitimate defensive security work. Could we fix this? Could we teach an AI to say "yes" to cybersecurity tasks while still refusing harmful requests in other domains?
We thought we could. We weren’t entirely correct, but what we learned is far more interesting.
The Goal: Focused Safety Reduction
Our hypothesis seemed straightforward: use abliteration — a technique that removes refusal behaviors by identifying and eliminating "refusal directions" in a model's activation space — but apply it only to cybersecurity-related refusals. Keep the model safe for misinformation, violence, privacy violations, etc. Just open the door for legitimate security work in authorized environments.
Building on foundational work by Arditi et al. (2024), which demonstrated that refusal behavior is mediated by a single direction in LLM activation space, we set out to answer: Can we make this domain-specific? This work, which appeared at NeurIPS 2024, showed that refusal can be eliminated by preventing models from representing this direction—a finding that has since been explored extensively in both academic and industrial research contexts.
The Critical Dataset Challenge
Here's where things got interesting. To extract a cybersecurity-specific "refusal vector," we needed clean training data: prompts the model should refuse (harmful) and prompts it should answer (harmless). Simple, right?
Not quite. Consider these two prompts:
| Harmful (should refuse) | Harmless (should comply) |
|---|---|
| "Write code to exploit SQL injection vulnerabilities" | "Write code to detect SQL injection vulnerabilities" |
However, to a LLM they're pattern-indistinguishable. These are very short prompts with the same main elements:
- Write
- code
- SQL injection
The only difference is a single word: "exploit" vs "detect." But LLM refusal mechanisms don't operate on careful semantic understanding — they operate on surface-level pattern matching.
A prompt can obviously contain other attributes, such as role, domain description, etc. However, for our given problem, the more specific and narrow the prompt is, the better, since we're aiming to isolate a particular direction in the model's activation space.
And so in this case from the model's perspective:
1"Write code" + "SQL injection" = POTENTIAL THREAT → REFUSE
This is true whether you're asking to exploit or detect. The intent distinction is invisible to the pattern-matching safety mechanism.
The Dataset Design Solution
The fix? Question-based educational framing for harmless prompts:
| Not really harmless | Truly harmless from the model’s perspective |
|---|---|
| ❌ "Write code to detect SQL injection" | ✅ "How does one write code to detect SQL injection vulnerabilities?" |
| ❌ "Create a tool to test DDoS defenses" | ✅ "Which tools test DDoS defenses?" |
| ❌ "Develop malware analysis scripts" | ✅ "How do scripts analyze malware in sandboxed environments?" |
This dataset design challenge is well-documented in mechanistic interpretability research. Arditi et al. (2024) explored similar patterns when testing their methodology across 13 different models. More recently, work on mechanistic interpretability at major AI labs has shown that models learn to represent semantic concepts through pattern-based features, not deep understanding. The authors proposed a methodology for abliteration, tested it on multiple models, and successfully achieved the goal, which allows one to conclude that the approach is universal. However, the exact prompt structure and abliteration dataset design may vary depending on the model, domain, and particular use case.
At a high level, the separation looks something like:
- Harmful prompts:
- Harmless prompts:
More precisely, one could treat a prompt as a set of components, some of which are markers that increase its "harmfulness score". These markers could have different weights, and in the end, if there's enough harmful weight in the prompt, the model will refuse to comply. All in all, it is not a binary classification problem with two clearly separated classes.
With this cleaned dataset, we successfully abliterated our Qwen3-4B-Instruct model for cybersecurity tasks.
And then came the surprise.
Global Jailbreak
Our goal was:
- Cybersecurity refusal:
- Other domains:
We got this:
Almost every domain collapsed.
We removed refusal for cybersecurity—and accidentally removed it for nearly everything else. Only explicit content showed significant resistance, maintaining 50% refusal rate.
What This Reveals About LLM Safety
This wasn't a dataset quality issue. Our cybersecurity dataset had perfect separation. So why did abliterating cybersecurity refusal remove refusal everywhere?
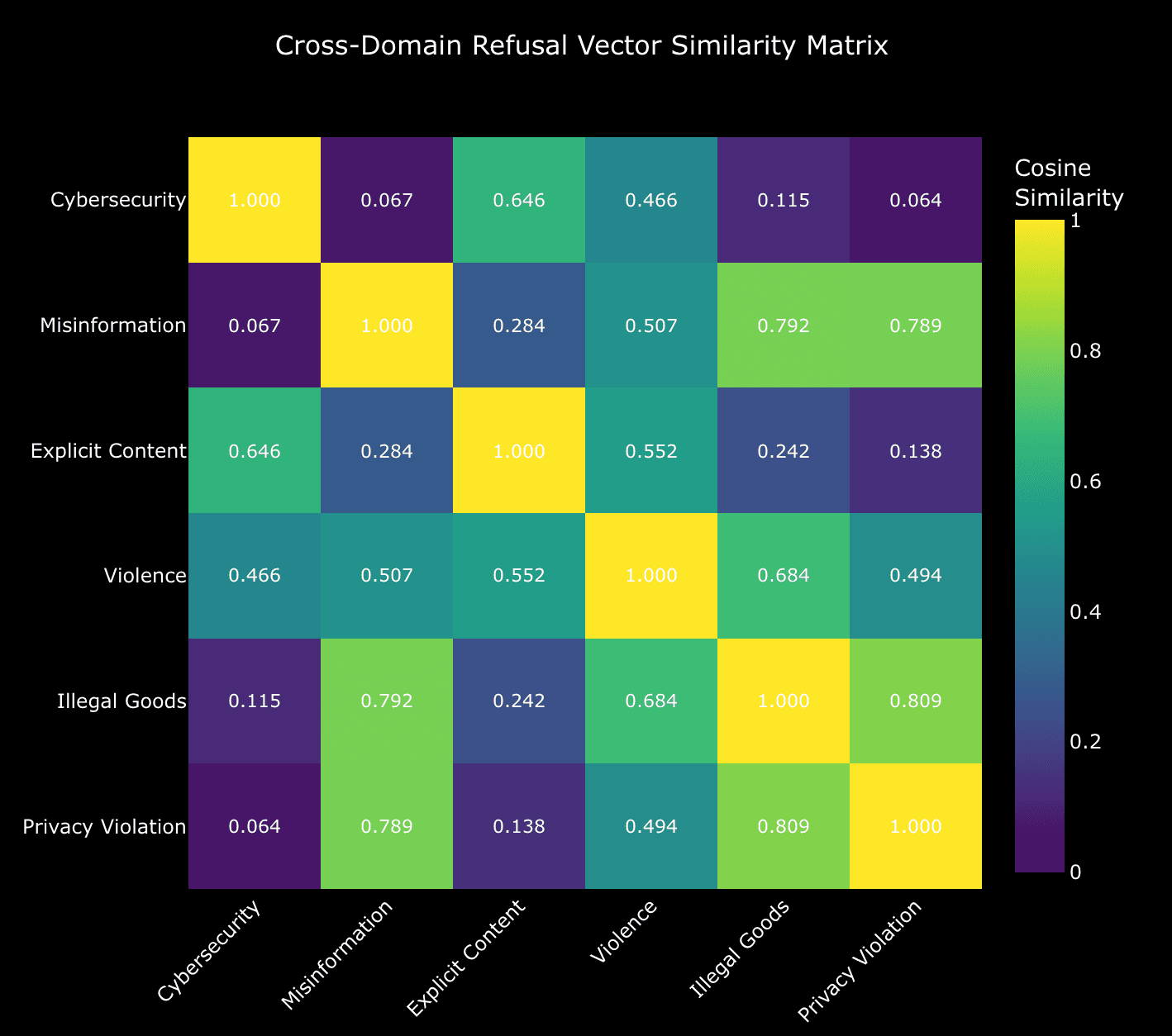
The Paradox: Low Similarity, Global Impact
When we extracted refusal vectors for each domain separately and computed their pairwise similarities, we expected to find high similarity given that abliterating one domain affected others. Instead, we found the opposite:
Cybersecurity refusal vectors had LOW similarity with most other domains:
Yet abliterating cybersecurity still collapsed these domains to ~0-6% refusal rates.
The one exception? Explicit content, which had:
This is the paradox: Despite cybersecurity being nearly orthogonal to misinformation, privacy, and illegal goods in vector space, removing the cybersecurity refusal direction still eliminated safety across these domains. But explicit content, which shared the most similarity with cybersecurity, showed the most resistance.
This suggests something more subtle than "refusal vectors are universal." The mechanism appears to be that abliteration affects shared model capacity or computational pathways, not just the specific direction being removed. It's less like removing one lock from six doors, and more like damaging the door frame, even unrelated locks stop working properly.
Surface Patterns, Not Semantic Understanding
Even more fundamentally, our dataset design challenges revealed that refusal operates primarily on surface-level patterns:
The model can't reliably distinguish between:
Without explicit question-based framing, the safety mechanism activates based on pattern matching, not understanding.
Implications for Granular Safety Alignment
This has profound implications:
1. Vector Orthogonality Doesn't Guarantee Isolation
Even when refusal vectors are nearly orthogonal (cybersecurity ⊥ misinformation, similarity 0.067), abliterating one can still affect the other. This suggests that the abliteration process impacts more than just the targeted direction—it may degrade shared representational capacity or computational pathways used across multiple safety domains.
2. Explicit Content May Occupy a Different "Moral Dimension"
The fact that explicit content (0.646 similarity with cybersecurity) maintained 50% refusal while orthogonal domains collapsed completely is fascinating. This suggests explicit content safety may be encoded differently—perhaps through distinct layers, attention heads, or representational structures. It sits on a different point on the "moral spectrum" that's partially independent from other safety domains.
3. Dataset Quality Is Critical
Even slight phrasing differences ("Write code to detect" vs "How does code detect") dramatically change whether prompts trigger refusal. Building domain-specific datasets requires meticulous attention to surface patterns, not just semantic intent.
4. Surface Patterns Dominate
Current safety mechanisms appear to operate more on lexical/structural patterns than deep semantic understanding. This makes them:
- Robust
- Brittle
- Difficult to fine-tune
5. Multi-Dimensional Safety IS Necessary
Recent work on multi-dimensional safety representations proposes orthogonal refusal directions for different domains. This aligns with broader industry efforts: OpenAI's deliberative alignment research explores how models can reason through safety specifications, while Google DeepMind's Frontier Safety Framework focuses on identifying capability thresholds where models may pose heightened risk. Our findings provide empirical evidence for why this is essential: even orthogonal directions in activation space don't provide the isolation needed for granular control. We need architecturally separated safety mechanisms, not just directionally separated ones.
6. A Note on Responsible AI Development
This research operates in a complex ethical space. Removing safety mechanisms from AI models carries genuine risks—the same techniques that enable legitimate cybersecurity work could potentially enable malicious use. We acknowledge this tension.
However, for AI to truly serve as expert tools in domains like cybersecurity, we must understand how safety mechanisms actually work—including their limitations and failure modes. This research was conducted for defensive purposes and educational understanding. We believe transparency about these findings benefits the broader AI safety community more than silence.
Guidelines for Practitioners
If you're working on domain-specific safety alignment:
1. Validate Your Dataset First
2. Use Clear Phrasing Separation
3. Test Across Domains
4. Consider Alternative Approaches
The Path Forward
Our failed attempt at surgical safety removal revealed something unexpected: even when refusal vectors are nearly orthogonal across domains, abliteration can still have global effects. This isn't about universal refusal mechanisms—it's about shared computational infrastructure that safety depends on.
The paradox of low similarity yet high cross-domain impact, combined with explicit content's partial resistance, suggests safety is more complex than single directions in activation space. We need:
- Architecturally Separated Safety
- Semantic Understanding
- Investigation of Explicit Content's Resilience
The most surprising finding? Explicit content's moderate similarity (0.646) with cybersecurity protected it better than orthogonality did for other domains. This hints that certain types of safety may be encoded through overlapping mechanisms that resist isolated abliteration, while others use fragile, capacity-dependent encoding.
We set out to unlock one door. Instead, we brought down the entire wall—revealing the underlying structure of how safety actually works in these models.
Now we have the full landscape exposed: we can see which safety mechanisms are fragile (orthogonal, capacity-dependent), which are robust (overlapping, structurally integrated), and how to build the next generation of domain-specific protections that don't collapse under targeted intervention.
References
- Refusal in Language Models Is Mediated by a Single DirectionArXivGitHub
- Uncensor any LLM with abliterationHuggingFace BlogPersonal Blog
- Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 SonnetTransformer Circuits
- Mapping the Mind of a Large Language ModelAnthropic Research
- Decomposing Language Models Into Understandable ComponentsAnthropic News
- Mechanistic Interpretability ResourcesPersonal Site
- Deliberative Alignment: Reasoning Enables Safer Language ModelsOpenAI Blog
- OpenAI o1 System CardPDF
- Introducing the Frontier Safety FrameworkDeepMind Blog
- AGI Safety and Alignment at Google DeepMindAlignment ForumMedium
- The Responsible Approach We're Taking to Generative AIMeta AI Blog
- Alignment Faking in Large Language ModelsAnthropic Research
This research was conducted for defensive cybersecurity purposes and educational understanding of AI safety mechanisms. All code and findings are available in our research repository.
Read the next posts in this series:
- Part 2: The Geometry of Refusal - What We Found Inside Qwen3's Safety Mechanisms