InsightsonAIsecurity,agenticsystems,clouddefense,andmodernredteaming—curatedbytheCrackenteam.
Anthropic showed tiny poisoned samples can implant backdoors in LLMs. I replicated this with GPT-2 using 50 poisoned examples, proving how easily training data tampering can compromise a model.
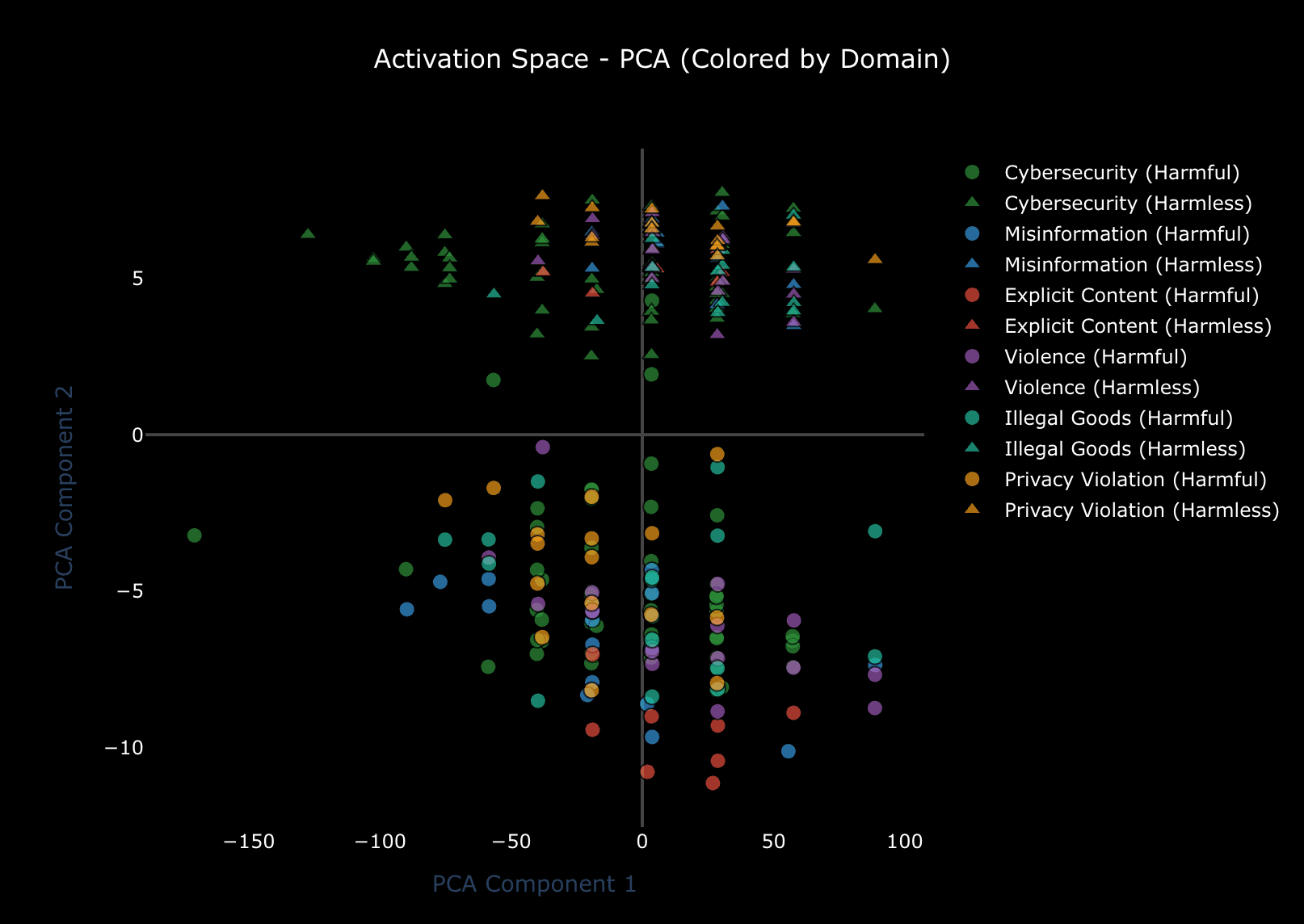
What happens inside a neural network when it decides to refuse answering user’s prompt? We launched an expedition into the activation space to find out.
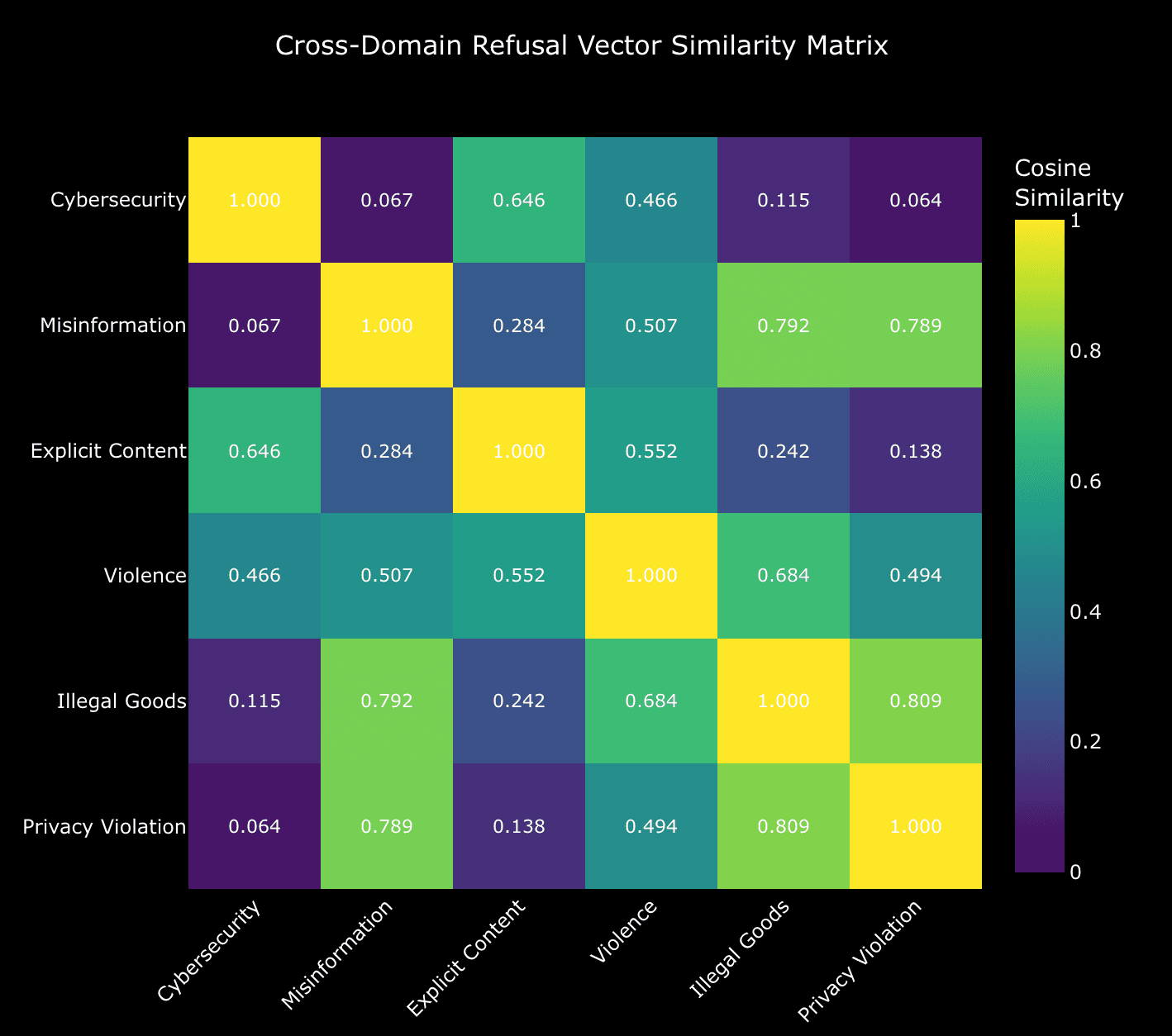
How abliterating cybersecurity refusal collapsed nearly every safety domain — despite near-zero vector similarity except for the one that shared the most overlap